关键词: setup hold recovery removal width period
指定路径延迟,目的是让仿真的时序更加接近实际数字电路的时序。利用时序约束对数字设计进行时序仿真,检查设计是否存在违反(violation)时序约束的地方,并加以修改,也是数字设计中不可或缺的过程。
Verilog 提供了一些系统任务,用于时序检查。这些系统任务只能在 specify 块中调用。下面就介绍 6 种常用的用于时序检查的系统任务:$setup, $hold, $recovery, $removal, $width 与 $period。
$setup, $hold
系统任务 $setup 用来检查设计中元件的建立时间约束条件,$hold 用来检查保持时间约束条件。其用法格式如下:
$setup(data_event, ref_event, setup_limit);- data_event: 被检查的信号,判断它是否违反约束
- ref_event: 用于检查的参考信号,一般为时钟信号的跳变沿
- setup_limit: 设置的最小建立时间
如果 T( ref_event - data_event) < setup_limit, 则会打印存在 violation 的报告。
$hold(ref_event, data_event, hold_limit);如果 T( data_event - ref_event ) < hold_limit, 则会打印存在 violation 的报告。
注意: $setup 和 $hold 输入端口的位置是不同的。
Verilog 提供了同时检查建立时间和保持时间的系统任务:
$setuphold (ref_event, data_event, setup_limit, hold_limit);下面完成一个数乘以 15 的操作,来说明 $setup 和 $hold 的用法。
Verilog 中,一个变量乘以常数一般用移位相加的方法来完成,例如对变量 num 乘以 15 的操作可以表示为:
num x 15 = (num << 3) + (num << 2) + (num << 1) + num全加器功能描述可参考《Verilog 教程》的 3.1 节内容。
实例
//单 bit 全加器,指定路径延迟
module full_adder1(
input Ai, Bi, Ci,
output So, Co);
assign So = Ai ^ Bi ^ Ci ;
assign Co = (Ai & Bi) | (Ci & (Ai | Bi));
specify
(Ai, Bi, Ci *> So) = 1.1 ;
(Ai, Bi *> Co) = 1.3 ;
(Ci => Co) = 1.2 ;
endspecify
endmodule
//8bit 位宽加法器例化
module full_adder8(
input [7:0] a , //adder1
input [7:0] b , //adder2
input c , //input carry bit
output [7:0] so , //adding result
output co //output carry bit
);
wire [7:0] co_temp ;
full_adder1 u_adder0(
.Ai (a[0]),
.Bi (b[0]),
.Ci (c==1'b1 ? 1'b1 : 1'b0),
.So (so[0]),
.Co (co_temp[0]));
genvar i ;
generate
for(i=1; i<=7; i=i+1) begin: adder_gen
full_adder1 u_adder(
.Ai (a[i]),
.Bi (b[i]),
.Ci (co_temp[i-1]),
.So (so[i]),
.Co (co_temp[i]));
end
endgenerate
assign co = co_temp[7] ;
endmodule
//单 bit 全加器,指定路径延迟
module full_adder1(
input Ai, Bi, Ci,
output So, Co);
assign So = Ai ^ Bi ^ Ci ;
assign Co = (Ai & Bi) | (Ci & (Ai | Bi));
specify
(Ai, Bi, Ci *> So) = 1.1 ;
(Ai, Bi *> Co) = 1.3 ;
(Ci => Co) = 1.2 ;
endspecify
endmodule
//8bit 位宽加法器例化
module full_adder8(
input [7:0] a , //adder1
input [7:0] b , //adder2
input c , //input carry bit
output [7:0] so , //adding result
output co //output carry bit
);
wire [7:0] co_temp ;
full_adder1 u_adder0(
.Ai (a[0]),
.Bi (b[0]),
.Ci (c==1'b1 ? 1'b1 : 1'b0),
.So (so[0]),
.Co (co_temp[0]));
genvar i ;
generate
for(i=1; i<=7; i=i+1) begin: adder_gen
full_adder1 u_adder(
.Ai (a[i]),
.Bi (b[i]),
.Ci (co_temp[i-1]),
.So (so[i]),
.Co (co_temp[i]));
end
endgenerate
assign co = co_temp[7] ;
endmodule
8bit 位宽的触发器描述如下。触发器中指定路径延迟,并加入建立时间和保持时间的时序检查。
建立时间设置为 2ns,保持时间设置为 3ns。
实例
module D8(
input [7:0] d ,
input clk ,
output reg [7:0] q);
always @(posedge clk)
q <= d ;
specify
$setup(d, posedge clk, 2);
$hold(posedge clk, d, 3);
(d,clk *> q) = 0.3 ;
endspecify
endmodule
在 testbench 里完成乘以 15 的操作,并在一个周期内输出给下一级寄存器。实例
`timescale 1ns/1ns
module test ;
reg [3:0] a ;
reg [3:0] b ;
wire [3:0] so ;
wire co ;
parameter CYCLE_10NS = 10ns;
reg clk ;
initial begin
clk = 0 ;
# 111 ;
forever begin
#(CYCLE_10NS/2) clk = ~clk ;
end
end
//需要乘以 15 的数
reg [7:0] num = 0 ;
always @(posedge clk) begin
num[3:0] <= num[3:0] + 1 ;
end
// num * 8 + num * 4
wire [7:0] adder1 ;
full_adder8 u1_adder8(
.a (num<<2),
.b (num<<3),
.c (1'b0),
.so (adder1),
.co ());
//num * 2 + num
wire [7:0] adder2 ;
full_adder8 u2_adder8(
.a (num<<1),
.b (num),
.c (1'b0),
.so (adder2),
.co ());
//num x 15
wire [7:0] adder3 ;
full_adder8 u3_adder8(
.a (adder1),
.b (adder2),
.c (1'b0),
.so (adder3),
.co ());
//store the result
wire [7:0] res_mul15 ;
D8 data_store(
.d (adder3),
.clk (clk),
.q (res_mul15));
initial begin
forever begin
#100;
if ($time >= 1000) $finish ;
end
end
endmodule // test
仿真报告中则出现了带有 setup/hold violation 的打印信息,部分截图如下。
module D8(
input [7:0] d ,
input clk ,
output reg [7:0] q);
always @(posedge clk)
q <= d ;
specify
$setup(d, posedge clk, 2);
$hold(posedge clk, d, 3);
(d,clk *> q) = 0.3 ;
endspecify
endmodule
`timescale 1ns/1ns
module test ;
reg [3:0] a ;
reg [3:0] b ;
wire [3:0] so ;
wire co ;
parameter CYCLE_10NS = 10ns;
reg clk ;
initial begin
clk = 0 ;
# 111 ;
forever begin
#(CYCLE_10NS/2) clk = ~clk ;
end
end
//需要乘以 15 的数
reg [7:0] num = 0 ;
always @(posedge clk) begin
num[3:0] <= num[3:0] + 1 ;
end
// num * 8 + num * 4
wire [7:0] adder1 ;
full_adder8 u1_adder8(
.a (num<<2),
.b (num<<3),
.c (1'b0),
.so (adder1),
.co ());
//num * 2 + num
wire [7:0] adder2 ;
full_adder8 u2_adder8(
.a (num<<1),
.b (num),
.c (1'b0),
.so (adder2),
.co ());
//num x 15
wire [7:0] adder3 ;
full_adder8 u3_adder8(
.a (adder1),
.b (adder2),
.c (1'b0),
.so (adder3),
.co ());
//store the result
wire [7:0] res_mul15 ;
D8 data_store(
.d (adder3),
.clk (clk),
.q (res_mul15));
initial begin
forever begin
#100;
if ($time >= 1000) $finish ;
end
end
endmodule // test
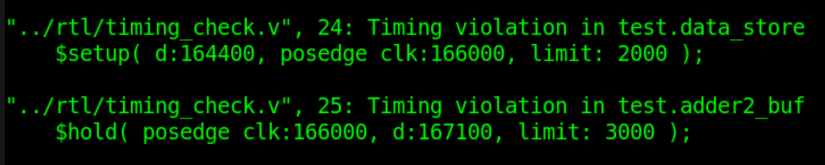
截取出现 violation 时间的波形图,如下所示。
分析如下:
- (1) 建立时间和保持时间均出现了 violation,虽然仿真中变量 num 乘以 15 以后延迟一个时钟周期的输出结果是正确的,但实际电路是很危险的。
- (2) 波形中信号的建立时间 166-164.4 = 1.6 ns,小于设置的 2ns,所以会报告 violation。
- (3) 波形中信号的保持时间 168.2-166 = 2.2 ns,小于设置的 3ns,所以会报告 violation。
- (4) 图中红色部分是信号 d 变化的中间过程,因为信号各 bit 延迟不同,所以中间可能会出现多个不同的结果。
时序优化
保持时间的时序优化,在 RTL 层级描述上一般不好控制,这属于后端设计工程师的工作范畴,这里不做讨论。
本次主要简单探讨建立时间不满足约束条件时的优化问题。由上一节《3.3 建立时间和保持时间》中可知建立时间约束表达式为:
Tcq + Tcomb + Tsu <= Tclk + Tskew (1)优化此不等式可从以下几个方面考虑:
- (1) 选取时序较好的工艺原件,其 Tcq 和 Tsu 值越小越好;
- (2) 优化组合逻辑,使组合逻辑延迟 Tcomb 越小越好;
- (3) 降低工作时钟频率,增大工作时钟周期 Tclk;
- (4) 增加时钟偏移 Tskew,但时钟偏移过大又会造成其他问题,例如保持时间可能不满足,功能逻辑错误等。
从 RTL 层次进行时序优化时,只能考虑方法(2)(3)。
例如,将上述仿真中的工作时钟周期由 10ns 改为 20ns,则不会出现 setup violation。
或者,调整逻辑,一个周期内完成 3 次加法运算,改为分散到两个周期内完成,中间增加一级寄存器进行缓冲,来减少时序上的压力。同时,变量 num 的变化周期也应该变为原来的 2 倍时长。
testbench 修改如下:
实例
`timescale 1ns/1ns
`define LOGIC_BUF
module test ;
parameter CYCLE_10NS = 10ns;
reg clk ;
initial begin
clk = 0 ;
# 111 ;
forever begin
#(CYCLE_10NS/2) clk = ~clk ;
end
end
reg slow_flag = 0 ;
always @(posedge clk) begin
`ifdef LOGIC_BUF
slow_flag <= ~slow_flag ;
`else
slow_flag <= 1'b1 ;
`endif
end
reg [7:0] num = 0 ;
always @(posedge clk) begin
if(slow_flag)
num[3:0] <= num[3:0] + 1 ;
end
wire [7:0] adder1 ;
full_adder8 u1_adder8(
.a (num<<2),
.b (num<<3),
.c (1'b0),
.so (adder1),
.co ());
wire [7:0] adder2 ;
full_adder8 u2_adder8(
.a (num<<1),
.b (num),
.c (1'b0),
.so (adder2),
.co ());
//====== for better time=========
//adding buffer
wire [7:0] adder1_r, adder2_r ;
D8 adder1_buf(
.d (adder1),
.clk (clk),
.q (adder1_r));
D8 adder2_buf(
.d (adder2),
.clk (clk),
.q (adder2_r));
`ifdef LOGIC_BUF
wire [7:0] adder1_t = adder1_r ;
wire [7:0] adder2_t = adder2_r ;
`else
wire [7:0] adder1_t = adder1 ;
wire [7:0] adder2_t = adder2 ;
`endif
wire [7:0] adder3 ;
full_adder8 u3_adder8(
.a (adder1_t),
.b (adder2_t),
.c (1'b0),
.so (adder3),
.co ());
wire [7:0] res_mul15 ;
D8 data_store(
.d (adder3),
.clk (clk),
.q (res_mul15));
initial begin
forever begin
#100;
if ($time >= 1000) $finish ;
end
end
endmodule // test
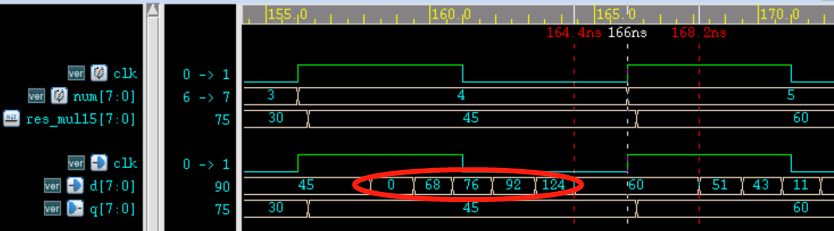
此时仿真报告中不再有 violation,仿真截图如下。
`timescale 1ns/1ns
`define LOGIC_BUF
module test ;
parameter CYCLE_10NS = 10ns;
reg clk ;
initial begin
clk = 0 ;
# 111 ;
forever begin
#(CYCLE_10NS/2) clk = ~clk ;
end
end
reg slow_flag = 0 ;
always @(posedge clk) begin
`ifdef LOGIC_BUF
slow_flag <= ~slow_flag ;
`else
slow_flag <= 1'b1 ;
`endif
end
reg [7:0] num = 0 ;
always @(posedge clk) begin
if(slow_flag)
num[3:0] <= num[3:0] + 1 ;
end
wire [7:0] adder1 ;
full_adder8 u1_adder8(
.a (num<<2),
.b (num<<3),
.c (1'b0),
.so (adder1),
.co ());
wire [7:0] adder2 ;
full_adder8 u2_adder8(
.a (num<<1),
.b (num),
.c (1'b0),
.so (adder2),
.co ());
//====== for better time=========
//adding buffer
wire [7:0] adder1_r, adder2_r ;
D8 adder1_buf(
.d (adder1),
.clk (clk),
.q (adder1_r));
D8 adder2_buf(
.d (adder2),
.clk (clk),
.q (adder2_r));
`ifdef LOGIC_BUF
wire [7:0] adder1_t = adder1_r ;
wire [7:0] adder2_t = adder2_r ;
`else
wire [7:0] adder1_t = adder1 ;
wire [7:0] adder2_t = adder2 ;
`endif
wire [7:0] adder3 ;
full_adder8 u3_adder8(
.a (adder1_t),
.b (adder2_t),
.c (1'b0),
.so (adder3),
.co ());
wire [7:0] res_mul15 ;
D8 data_store(
.d (adder3),
.clk (clk),
.q (res_mul15));
initial begin
forever begin
#100;
if ($time >= 1000) $finish ;
end
end
endmodule // test
由图可知,信号提前到达并保持不变的时间可达 8.6 ns,完全满足建立时间的时序要求。
此种方法的根本原理,是将信号多次变化的时序,分散在多个周期内,来满足时序约束的要求。此外,流水线设计,并行设计等都可以优化时序。
$recovery, $removal
建立时间和保持时间的概念都是出现在同步电路的设计中。
对于异步复位的触发器来说,异步复位信号也需要满足 recovery time(恢复时间)和 removal time(去除时间),才能有效的复位和释放复位,防止出现亚稳态。
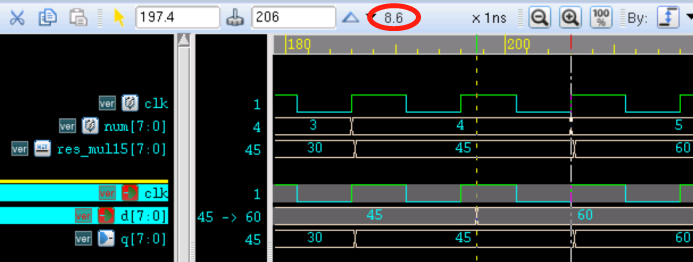
释放复位时,复位信号在时钟有效沿来临之前就需要提前一段时间恢复到非复位状态,这段时间为 recovery time。类似于同步时钟下触发器的 setup time。
复位时,复位信号在时钟有效沿来临之后,还需要在一段时间内保持不变,这段时间为 removal time。类似于同步时钟下触发器的 hold time。
recovery 与 removal time 示意图如下所示。
系统任务 $recovery 与 $removal 分别用于 recovery 和 removal time 的检查,用法如下:
$recovery (ref_event, data_event, recovery_limit) ;当 ref_event (reset) < data_event (clock) 且 T(data_event - ref_event) < recovery_limit 时,即复位信号在时钟信号到来之前如果不满足 recovery time,则报告中会打印 violation。
$removal (ref_event, data_event, removal_limit) ;当 ref_event (reset) > data_event (clock) 且 T(ref_event - data_event) > removal_limit 时,即复位信号在时钟信号到来之后如果不满足 removal time,则报告中会打印 violation。
Verilog 提供了同时检查 revomal 和 recovery 的系统任务:
$recrem (ref_event, data_event, recovery_limit, removal_limit);$width, $period
有些数字设计,例如 flash 存储器,还需要对脉冲宽度或周期进行检查,为此 Verilog 分别提供了系统任务 $width 和 $period。用法如下:
$width(ref_event, time_limit) ;$width 用于检查边沿触发事件 ref_event 到下一个反向跳变沿之间的时间,常用于脉冲宽度的检查。如果两次相反跳边沿之间的时间小于 time_limit,则会报告 violation。
$period(ref_event, time_limit) ;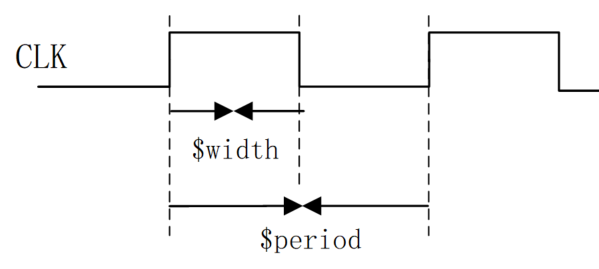
检查信号 CLK 宽度和周期的 specify 块描述如下:
实例
specify
$width(posedge CLK, 10);
$period(posedge CLK, 20);
endspecify
本章节源码下载
specify
$width(posedge CLK, 10);
$period(posedge CLK, 20);
endspecify