Pandas CSV 文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
Pandas 可以很方便的处理 CSV 文件,本文以 nba.csv 为例,你可以下载 nba.csv 或打开 nba.csv 查看。
实例
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 ... 代替。
实例
import pandas as pd
df = pd.read_csv('nba.csv')
print(df)
输出结果为:
Name Team Number Position Age Height Weight College Salary
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0
.. ... ... ... ... ... ... ... ... ...
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN NaN NaN NaN NaN NaN
import pandas as pd
df = pd.read_csv('nba.csv')
print(df)
Name Team Number Position Age Height Weight College Salary
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0
.. ... ... ... ... ... ... ... ... ...
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN NaN NaN NaN NaN NaN
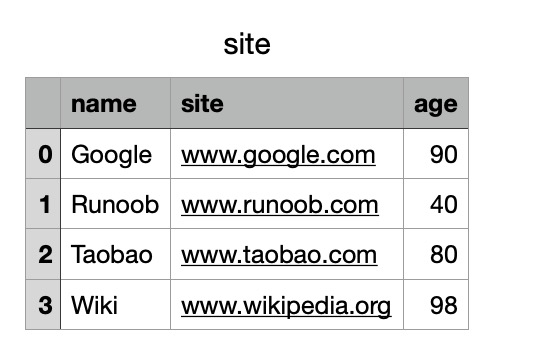
我们也可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件:
实例
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.zhishitu.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
执行成功后,我们打开 site.csv 文件,显示结果如下:
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.zhishitu.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
数据处理
head()
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
实例 - 读取前面 5 行
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())
输出结果为:
Name Team Number Position Age Height Weight College Salary
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0实例 - 读取前面 10 行
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head(10))
输出结果为:
Name Team Number Position Age Height Weight College Salary
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0
5 Amir Johnson Boston Celtics 90.0 PF 29.0 6-9 240.0 NaN 12000000.0
6 Jordan Mickey Boston Celtics 55.0 PF 21.0 6-8 235.0 LSU 1170960.0
7 Kelly Olynyk Boston Celtics 41.0 C 25.0 7-0 238.0 Gonzaga 2165160.0
8 Terry Rozier Boston Celtics 12.0 PG 22.0 6-2 190.0 Louisville 1824360.0
9 Marcus Smart Boston Celtics 36.0 PG 22.0 6-4 220.0 Oklahoma State 3431040.0
tail()
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head(10))
Name Team Number Position Age Height Weight College Salary
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0
5 Amir Johnson Boston Celtics 90.0 PF 29.0 6-9 240.0 NaN 12000000.0
6 Jordan Mickey Boston Celtics 55.0 PF 21.0 6-8 235.0 LSU 1170960.0
7 Kelly Olynyk Boston Celtics 41.0 C 25.0 7-0 238.0 Gonzaga 2165160.0
8 Terry Rozier Boston Celtics 12.0 PG 22.0 6-2 190.0 Louisville 1824360.0
9 Marcus Smart Boston Celtics 36.0 PG 22.0 6-4 220.0 Oklahoma State 3431040.0tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
实例 - 读取末尾 5 行
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail())
输出结果为: Name Team Number Position Age Height Weight College Salary
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN NaN NaN NaN NaN NaN
实例 - 读取末尾 10 行
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail(10))
输出结果为:
Name Team Number Position Age Height Weight College Salary
448 Gordon Hayward Utah Jazz 20.0 SF 26.0 6-8 226.0 Butler 15409570.0
449 Rodney Hood Utah Jazz 5.0 SG 23.0 6-8 206.0 Duke 1348440.0
450 Joe Ingles Utah Jazz 2.0 SF 28.0 6-8 226.0 NaN 2050000.0
451 Chris Johnson Utah Jazz 23.0 SF 26.0 6-6 206.0 Dayton 981348.0
452 Trey Lyles Utah Jazz 41.0 PF 20.0 6-10 234.0 Kentucky 2239800.0
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN NaN NaN NaN NaN NaN
info()
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail())
Name Team Number Position Age Height Weight College Salary
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN NaN NaN NaN NaN NaN
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail(10))
Name Team Number Position Age Height Weight College Salary
448 Gordon Hayward Utah Jazz 20.0 SF 26.0 6-8 226.0 Butler 15409570.0
449 Rodney Hood Utah Jazz 5.0 SG 23.0 6-8 206.0 Duke 1348440.0
450 Joe Ingles Utah Jazz 2.0 SF 28.0 6-8 226.0 NaN 2050000.0
451 Chris Johnson Utah Jazz 23.0 SF 26.0 6-6 206.0 Dayton 981348.0
452 Trey Lyles Utah Jazz 41.0 PF 20.0 6-10 234.0 Kentucky 2239800.0
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN NaN NaN NaN NaN NaNinfo()
info() 方法返回表格的一些基本信息:
实例
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())
输出结果为:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 458 entries, 0 to 457 # 行数,458 行,第一行编号为 0
Data columns (total 9 columns): # 列数,9列
# Column Non-Null Count Dtype # 各列的数据类型
--- ------ -------------- -----
0 Name 457 non-null object
1 Team 457 non-null object
2 Number 457 non-null float64
3 Position 457 non-null object
4 Age 457 non-null float64
5 Height 457 non-null object
6 Weight 457 non-null float64
7 College 373 non-null object # non-null,意思为非空的数据
8 Salary 446 non-null float64
dtypes: float64(4), object(5) # 类型